题目描述: 阿里云天池官网,天猫复购预测之挑战Baseline:https://tianchi.aliyun.com/competition/entrance/231576/rankingList
1.任务描述: 双十一活动通常可以为商家带来很多新客户,但其中只有一小部分会成为其忠实客户。对于商家来说,准确识别出哪些消费者更可能再次从他这购买产品,可以让商家更有针对性的做营销运营,从而减少成本,提升投资回报。
本分析报告选取了来自天池的公开数据集(详见天猫复购数据),旨在根据消费者双十一前6个月和双十一当天的购物记录信息,预测其在特定商家的复购概率。
本报告分为几部分:首先清洗数据,然后根据已有数据构建特征,再根据特征训练模型,最后选取表现最优的模型进行预测。
2.选题背景: 商家有时会在特定日期,例如Boxing-day,黑色星期五或是双十一(11月11日)开展大型促销活动或者发放优惠券以吸引消费者,然而很多被吸引来的买家都是一次性消费者,这些促销活动可能对销售业绩的增长并没有长远帮助,因此为解决这个问题,商家需要识别出哪类消费者可以转化为重复购买者。通过对这些潜在的忠诚客户进行定位,商家可以大大降低促销成本,提高投资回报率(Return on Investment, ROI)。众所周知的是,在线投放广告时精准定位客户是件比较难的事情,尤其是针对新消费者的定位。不过,利用天猫长期积累的用户行为日志,我们或许可以解决这个问题。
我们提供了一些商家信息,以及在“双十一”期间购买了对应产品的新消费者信息。你的任务是预测给定的商家中,哪些新消费者在未来会成为忠实客户,即需要预测这些新消费者在6个月内再次购买的概率。
3.数据描述: 数据集包含了匿名用户在 “双十一 “前6个月和”双十一 “当天的购物记录,标签为是否是重复购买者。出于隐私保护,数据采样存在部分偏差,该数据集的统计结果会与天猫的实际情况有一定的偏差,但不影响解决方案的适用性。训练集和测试集数据见文件data_format2.zip,数据详情见下表。
我们还以另一种格式提供了相同数据集,可能更方便做特征工程,详情见data_format1.zip文件夹(内含4个文件),数据描述如下。
字段名称
描述
user_id
购物者的唯一ID编码
item_id
商品的唯一编码
cat_id
商品所属品类的唯一编码
merchant_id
商家的唯一ID编码
brand_id
商品品牌的唯一编码
time_tamp
购买时间(格式:mmdd)action_type包含{0, 1, 2, 3},0表示单击,1表示添加到购物车,2表示购买,3表示添加到收藏夹
字段名称
描述
user_id
购物者的唯一ID编码
age_range
用户年龄范围。
gender
用户性别。0表示女性,1表示男性,2和NULL表示未知
字段名称
描述
user_id
购物者的唯一ID编码
merchant_id
商家的唯一ID编码
label
包含{0, 1},1表示重复买家,0表示非重复买家。测试集这一部分需要预测,因此为空。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns'display.max_columns' , 30 )"font.family" :"SimHei" ,"font.size" :14 })"tableau-colorblind10" )
1. 数据清洗 清洗步骤:
1 2 3 4 5 "./data/user_info_format1.csv" )"./data/train_format1.csv" )"./data/test_format1.csv" )
压缩内存:调整数据类型,将原来int64调整为合适的大小,例如:int32、int16、int8,以达到压缩内存的目的。
1 2 3 'user_id' : 'int32' , 'item_id' : 'int32' , 'cat_id' : 'int16' , 'seller_id' : 'int16' , 'brand_id' : 'float32' , 'time_stamp' : 'int16' , 'action_type' : 'int8' }"./data/user_log_format1.csv" ,dtype = d_types)
1 2 3 4 5 1 ))1 ))1 ))1 ))
user_id
item_id
cat_id
seller_id
brand_id
time_stamp
action_type
0
328862
323294
833
2882
2661.0
829
0
user_id
age_range
gender
0
376517
6.0
1.0
user_id
merchant_id
label
0
34176
3906
0
user_id
merchant_id
prob
0
163968
4605
NaN
1.1 数据类型检查 1 2 3 4 5
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 54925330 entries, 0 to 54925329
Data columns (total 7 columns):
# Column Dtype
--- ------ -----
0 user_id int32
1 item_id int32
2 cat_id int16
3 seller_id int16
4 brand_id float32
5 time_stamp int16
6 action_type int8
dtypes: float32(1), int16(3), int32(2), int8(1)
memory usage: 995.2 MB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 424170 entries, 0 to 424169
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 424170 non-null int64
1 age_range 421953 non-null float64
2 gender 417734 non-null float64
dtypes: float64(2), int64(1)
memory usage: 9.7 MB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 260864 entries, 0 to 260863
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 260864 non-null int64
1 merchant_id 260864 non-null int64
2 label 260864 non-null int64
dtypes: int64(3)
memory usage: 6.0 MB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 261477 entries, 0 to 261476
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 261477 non-null int64
1 merchant_id 261477 non-null int64
2 prob 0 non-null float64
dtypes: float64(1), int64(2)
memory usage: 6.0 MB
None
训练集和测试集都有约26万条数据。
1.2 压缩数据 1 2 3 4 5 6 "origin" ] = "train" "origin" ] = "test" False )"prob" ],axis = 1 )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 522341 entries, 0 to 261476
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 522341 non-null int64
1 merchant_id 522341 non-null int64
2 label 260864 non-null float64
3 origin 522341 non-null object
dtypes: float64(1), int64(2), object(1)
memory usage: 19.9+ MB
1 2 3 4 5 6 7 8 9 10 11 12 13 list = [data,data_user_log,data_user_info]list = [data,data_user_info]for df in list :'float' ).columns'integer' ).columns'float' )'integer' )
1 2 3 4
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 54925330 entries, 0 to 54925329
Data columns (total 7 columns):
# Column Dtype
--- ------ -----
0 user_id int32
1 item_id int32
2 cat_id int16
3 seller_id int16
4 brand_id float32
5 time_stamp int16
6 action_type int8
dtypes: float32(1), int16(3), int32(2), int8(1)
memory usage: 995.2 MB
None
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 424170 entries, 0 to 424169
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 424170 non-null int32
1 age_range 421953 non-null float32
2 gender 417734 non-null float32
dtypes: float32(2), int32(1)
memory usage: 4.9 MB
None
<class 'pandas.core.frame.DataFrame'>
Int64Index: 522341 entries, 0 to 261476
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 522341 non-null int32
1 merchant_id 522341 non-null int16
2 label 260864 non-null float32
3 origin 522341 non-null object
dtypes: float32(1), int16(1), int32(1), object(1)
memory usage: 13.0+ MB
None
1 2 3 4 5 for i in data_user_log.dtypes.values]dict (zip (d_col,d_type))print (column_dict)
{'user_id': 'int32', 'item_id': 'int32', 'cat_id': 'int16', 'seller_id': 'int16', 'brand_id': 'float32', 'time_stamp': 'int16', 'action_type': 'int8'}
1 2 "seller_id" :"merchant_id" },inplace = True )
1.3 空值处理 1 2 3 4 5 "age_range" ].fillna(0 ,inplace = True ) "gender" ].fillna(0 ,inplace = True )
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 424170 entries, 0 to 424169
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 424170 non-null int32
1 age_range 424170 non-null float32
2 gender 424170 non-null float32
dtypes: float32(2), int32(1)
memory usage: 4.9 MB
1 2 sum ()
user_id 0
item_id 0
cat_id 0
merchant_id 0
brand_id 91015
time_stamp 0
action_type 0
dtype: int64
1 2 "brand_id" ].fillna(0 , inplace = True )
1.4 数据初步探索 下一步对数据进行初步可视化,检视数据特征。
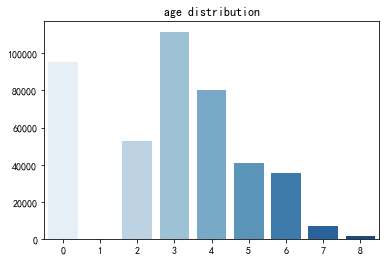
1 2 3 4 5 6 7 8 9 "index" ] = range (len (tags))"index" , y="age_range" , data=age, palette="Blues" )10 )'age distribution' ,fontsize=12 )'' )'' )
Text(0, 0.5, '')
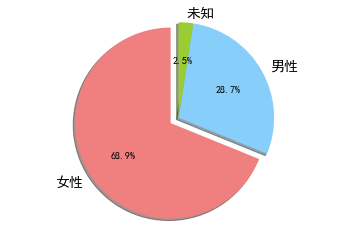
1 2 3 4 5 6 7 8 9 10 11 12 13 14 '女性' , '男性' , '未知' ]'lightcoral' , 'lightskyblue' , 'yellowgreen' ]0.1 , 0 , 0 )'%1.1f%%' , shadow=True , startangle=90 )'equal' )for t in l_text:14 )for t in p_text:10 )
用户年龄1表示<18岁,2表示18-24岁,3表示25-29岁,4表示30-34岁,5表示35-39岁,6表示40-49岁,7、8表示50岁以上,0表示未知。
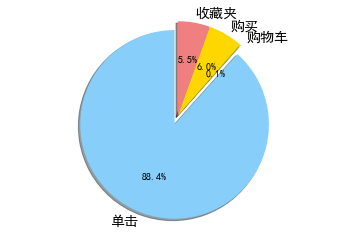
1 2 3 4 5 6 7 8 9 10 11 12 13 14 '单击' , '购物车' , '购买' , '收藏夹' ] 'lightskyblue' , 'yellowgreen' , 'gold' , 'lightcoral' ] 0.1 , 0 , 0 , 0 ) '%1.1f%%' , shadow=True , startangle=90 )'equal' ) for t in l_text:14 )for t in p_text:10 )
操作类型中0表示单击,1表示添加到购物车,2表示购买,3表示添加到收藏夹。
2. 构建特征 从业务上思考可能影响复购的因素有:
用户特征:年龄,性别,喜好的产品类型,购买习惯(网购频率、购买点击比等),喜欢尝鲜还是习惯固定店家购买
商家特征:产品结构,流量(用户交互频次、交互天数),口碑(购买点击比),产品评价(用户复购率)
用户-商家特征:用户喜好与商家产品的相似性
因此我们针对用户、商家、用户-商家来分别构建以下特征:
交互次数、交互天数
交互过的商品、品类、品牌、用户/商家数
点击、加购物车、购买、收藏的操作次数
购买点击比
复购率
用户性别、年龄
2.1 用户特征 1 2 "user_id" ])
1 2 3 4 0 :"u1" })"user_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
0
34176
3906
0.0
train
451
1
34176
121
0.0
train
451
2
34176
4356
1.0
train
451
1 2 3 4 "time_stamp" :"u2" })"user_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
0
34176
3906
0.0
train
451
47
1
34176
121
0.0
train
451
47
2
34176
4356
1.0
train
451
47
1 2 3 4 5 'item_id' ,'cat_id' ,'merchant_id' ,'brand_id' ]].nunique().reset_index().rename(columns={'item_id' :'u3' ,'cat_id' :'u4' ,'merchant_id' :'u5' ,'brand_id' :'u6' })"user_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
0
34176
3906
0.0
train
451
47
256
45
109
108
1
34176
121
0.0
train
451
47
256
45
109
108
2
34176
4356
1.0
train
451
47
256
45
109
108
1 2 3 4 'action_type' ].value_counts().unstack().reset_index().rename(columns={0 :'u7' , 1 :'u8' , 2 :'u9' , 3 :'u10' })"user_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
1 2 "u11" ] = data["u9" ]/data["u7" ]
1 2 3 4 5 6 7 8 9 10 11 12 "action_type" ]==2 ].groupby(["user_id" ,"merchant_id" ])"time_stamp" :"n_days" })"label_um" ] = [(1 if x > 1 else 0 ) for x in temp_rb["n_days" ]]"user_id" ,"label_um" ]).size().unstack(fill_value=0 ).reset_index()"u12" ] = temp[1 ]/(temp[0 ]+temp[1 ])"user_id" ,"u12" ]],on ="user_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
u12
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
1 2 3 4 5 6 7 8 9 "user_id" ,how = "left" )"age_range" ],prefix = "age" )"gender" ],prefix = "gender" )1 )"age_range" ,"gender" ],inplace = True )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
u12
age_0.0
age_1.0
age_2.0
age_3.0
age_4.0
age_5.0
age_6.0
age_7.0
age_8.0
gender_0.0
gender_1.0
gender_2.0
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
2.2 商家特征 1 2 "merchant_id" ])
1 2 3 4 0 :"m1" })"merchant_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
u12
age_0.0
age_1.0
age_2.0
age_3.0
age_4.0
age_5.0
age_6.0
age_7.0
age_8.0
gender_0.0
gender_1.0
gender_2.0
m1
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
16269
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
79865
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
7269
1 2 3 4 "time_stamp" :"m2" })"merchant_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
u12
age_0.0
age_1.0
age_2.0
age_3.0
age_4.0
age_5.0
age_6.0
age_7.0
age_8.0
gender_0.0
gender_1.0
gender_2.0
m1
m2
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
16269
185
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
79865
185
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
0.045455
0
0
0
0
0
0
1
0
0
1
0
0
7269
155
1 2 3 4 5 'item_id' ,'cat_id' ,'user_id' ,'brand_id' ]].nunique().reset_index().rename(columns={'item_id' :'m3' ,'cat_id' :'m4' ,'user_id' :'m5' ,'brand_id' :'m6' })"merchant_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
...
age_3.0
age_4.0
age_5.0
age_6.0
age_7.0
age_8.0
gender_0.0
gender_1.0
gender_2.0
m1
m2
m3
m4
m5
m6
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
0
1
0
0
1
0
0
16269
185
308
20
5819
2
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
0
1
0
0
1
0
0
79865
185
1179
26
10931
2
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
0
1
0
0
1
0
0
7269
155
67
15
2281
2
3 rows × 34 columns
1 2 3 4 'action_type' ].value_counts().unstack().reset_index().rename(columns={0 :'m7' , 1 :'m8' , 2 :'m9' , 3 :'m10' })"merchant_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
...
age_7.0
age_8.0
gender_0.0
gender_1.0
gender_2.0
m1
m2
m3
m4
m5
m6
m7
m8
m9
m10
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
1
0
0
16269
185
308
20
5819
2
14870.0
28.0
410.0
961.0
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
1
0
0
79865
185
1179
26
10931
2
72265.0
121.0
4780.0
2699.0
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
1
0
0
7269
155
67
15
2281
2
6094.0
16.0
963.0
196.0
3 rows × 38 columns
1 2 "m11" ] = data["m9" ]/data["m7" ]
1 2 3 4 5 6 7 8 "merchant_id" ,"label_um" ]).size().unstack(fill_value=0 ).reset_index()"m12" ] = temp[1 ]/(temp[0 ]+temp[1 ])"merchant_id" ,"m12" ]],on ="merchant_id" ,how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
...
gender_0.0
gender_1.0
gender_2.0
m1
m2
m3
m4
m5
m6
m7
m8
m9
m10
m11
m12
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
1
0
0
16269
185
308
20
5819
2
14870.0
28.0
410.0
961.0
0.027572
0.048387
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
1
0
0
79865
185
1179
26
10931
2
72265.0
121.0
4780.0
2699.0
0.066145
0.053014
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
1
0
0
7269
155
67
15
2281
2
6094.0
16.0
963.0
196.0
0.158024
0.084444
3 rows × 40 columns
2.3 用户-商家特征 1 2 'user_id' ,'merchant_id' ])
1 2 3 4 0 :"um1" })"merchant_id" ,"user_id" ],how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
...
gender_1.0
gender_2.0
m1
m2
m3
m4
m5
m6
m7
m8
m9
m10
m11
m12
um1
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
16269
185
308
20
5819
2
14870.0
28.0
410.0
961.0
0.027572
0.048387
39
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
79865
185
1179
26
10931
2
72265.0
121.0
4780.0
2699.0
0.066145
0.053014
14
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
0
7269
155
67
15
2281
2
6094.0
16.0
963.0
196.0
0.158024
0.084444
18
3 rows × 41 columns
1 2 3 4 "time_stamp" :"um2" })"merchant_id" ,"user_id" ],how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
...
gender_2.0
m1
m2
m3
m4
m5
m6
m7
m8
m9
m10
m11
m12
um1
um2
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
16269
185
308
20
5819
2
14870.0
28.0
410.0
961.0
0.027572
0.048387
39
9
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
79865
185
1179
26
10931
2
72265.0
121.0
4780.0
2699.0
0.066145
0.053014
14
3
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
0
7269
155
67
15
2281
2
6094.0
16.0
963.0
196.0
0.158024
0.084444
18
2
3 rows × 42 columns
1 2 3 4 5 'item_id' ,'cat_id' ,'brand_id' ]].nunique().reset_index().rename(columns={'item_id' :'um3' ,'cat_id' :'um4' ,'brand_id' :'um5' })"merchant_id" ,"user_id" ],how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
...
m3
m4
m5
m6
m7
m8
m9
m10
m11
m12
um1
um2
um3
um4
um5
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
308
20
5819
2
14870.0
28.0
410.0
961.0
0.027572
0.048387
39
9
20
6
1
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
1179
26
10931
2
72265.0
121.0
4780.0
2699.0
0.066145
0.053014
14
3
1
1
1
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
67
15
2281
2
6094.0
16.0
963.0
196.0
0.158024
0.084444
18
2
2
1
1
3 rows × 45 columns
1 2 3 4 'action_type' ].value_counts().unstack().reset_index().rename(columns={0 :'um6' , 1 :'um7' , 2 :'um8' , 3 :'um9' })"merchant_id" ,"user_id" ],how = "left" )3 )
user_id
merchant_id
label
origin
u1
u2
u3
u4
u5
u6
u7
u8
u9
u10
u11
...
m7
m8
m9
m10
m11
m12
um1
um2
um3
um4
um5
um6
um7
um8
um9
0
34176
3906
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
14870.0
28.0
410.0
961.0
0.027572
0.048387
39
9
20
6
1
36.0
NaN
1.0
2.0
1
34176
121
0.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
72265.0
121.0
4780.0
2699.0
0.066145
0.053014
14
3
1
1
1
13.0
NaN
1.0
NaN
2
34176
4356
1.0
train
451
47
256
45
109
108
410.0
NaN
34.0
7.0
0.082927
...
6094.0
16.0
963.0
196.0
0.158024
0.084444
18
2
2
1
1
12.0
NaN
6.0
NaN
3 rows × 49 columns
1 2 "um10" ] = data["um8" ]/data["um6" ]
3. 建模预测 这里我们测试几种模型,并对比和观察各个模型的表现:
二元逻辑回归:针对二分类问题的经典模型,训练快
随机森林:可处理高维数据、大数据集,训练快
LightGBM:内存消耗少,可直接处理缺失值,训练快
XGBoost:支持并行化,通过正则化防止过拟合,可处理缺失值,适用于中低维数据
3.1 建模预处理 <class 'pandas.core.frame.DataFrame'>
Int64Index: 522341 entries, 0 to 522340
Data columns (total 50 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 522341 non-null int32
1 merchant_id 522341 non-null int16
2 label 260864 non-null float32
3 origin 522341 non-null object
4 u1 522341 non-null int64
5 u2 522341 non-null int64
6 u3 522341 non-null int64
7 u4 522341 non-null int64
8 u5 522341 non-null int64
9 u6 522341 non-null int64
10 u7 521981 non-null float64
11 u8 38179 non-null float64
12 u9 522341 non-null float64
13 u10 294859 non-null float64
14 u11 521981 non-null float64
15 u12 522341 non-null float64
16 age_0.0 522341 non-null uint8
17 age_1.0 522341 non-null uint8
18 age_2.0 522341 non-null uint8
19 age_3.0 522341 non-null uint8
20 age_4.0 522341 non-null uint8
21 age_5.0 522341 non-null uint8
22 age_6.0 522341 non-null uint8
23 age_7.0 522341 non-null uint8
24 age_8.0 522341 non-null uint8
25 gender_0.0 522341 non-null uint8
26 gender_1.0 522341 non-null uint8
27 gender_2.0 522341 non-null uint8
28 m1 522341 non-null int64
29 m2 522341 non-null int64
30 m3 522341 non-null int64
31 m4 522341 non-null int64
32 m5 522341 non-null int64
33 m6 522341 non-null int64
34 m7 522341 non-null float64
35 m8 518289 non-null float64
36 m9 522341 non-null float64
37 m10 522341 non-null float64
38 m11 522341 non-null float64
39 m12 522341 non-null float64
40 um1 522341 non-null int64
41 um2 522341 non-null int64
42 um3 522341 non-null int64
43 um4 522341 non-null int64
44 um5 522341 non-null int64
45 um6 462933 non-null float64
46 um7 9394 non-null float64
47 um8 522341 non-null float64
48 um9 96551 non-null float64
49 um10 462933 non-null float64
dtypes: float32(1), float64(17), int16(1), int32(1), int64(17), object(1), uint8(12)
memory usage: 154.4+ MB
1 2 3 4 5 6 7 'float' ).columns'integer' ).columns'float' )'integer' )
<class 'pandas.core.frame.DataFrame'>
Int64Index: 522341 entries, 0 to 522340
Data columns (total 50 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 522341 non-null int32
1 merchant_id 522341 non-null int16
2 label 260864 non-null float32
3 origin 522341 non-null object
4 u1 522341 non-null int16
5 u2 522341 non-null int16
6 u3 522341 non-null int16
7 u4 522341 non-null int16
8 u5 522341 non-null int16
9 u6 522341 non-null int16
10 u7 521981 non-null float32
11 u8 38179 non-null float32
12 u9 522341 non-null float32
13 u10 294859 non-null float32
14 u11 521981 non-null float32
15 u12 522341 non-null float32
16 age_0.0 522341 non-null int8
17 age_1.0 522341 non-null int8
18 age_2.0 522341 non-null int8
19 age_3.0 522341 non-null int8
20 age_4.0 522341 non-null int8
21 age_5.0 522341 non-null int8
22 age_6.0 522341 non-null int8
23 age_7.0 522341 non-null int8
24 age_8.0 522341 non-null int8
25 gender_0.0 522341 non-null int8
26 gender_1.0 522341 non-null int8
27 gender_2.0 522341 non-null int8
28 m1 522341 non-null int32
29 m2 522341 non-null int16
30 m3 522341 non-null int16
31 m4 522341 non-null int16
32 m5 522341 non-null int32
33 m6 522341 non-null int8
34 m7 522341 non-null float32
35 m8 518289 non-null float32
36 m9 522341 non-null float32
37 m10 522341 non-null float32
38 m11 522341 non-null float32
39 m12 522341 non-null float32
40 um1 522341 non-null int16
41 um2 522341 non-null int8
42 um3 522341 non-null int16
43 um4 522341 non-null int8
44 um5 522341 non-null int8
45 um6 462933 non-null float32
46 um7 9394 non-null float32
47 um8 522341 non-null float32
48 um9 96551 non-null float32
49 um10 462933 non-null float32
dtypes: float32(18), int16(12), int32(3), int8(16), object(1)
memory usage: 69.7+ MB
1 2 0 , inplace = True )
1 2 3 "origin" ]=="train" ].drop(["origin" ],axis = 1 )"origin" ]=="test" ].drop(["origin" ,"label" ],axis = 1 )
1 X,Y = train.drop(['label' ],axis=1 ),train['label' ]
1 2 3 from sklearn.model_selection import train_test_split0.2 )
1 2 3 print ("Ratio of positive samples in train dataset:" ,train_y.mean())print ("Ratio of positive samples in valid dataset:" ,valid_y.mean())
Ratio of positive samples in train dataset: 0.06123886629939079
Ratio of positive samples in valid dataset: 0.06079773232340813
train、valid集正样本比例基本一致。
1 2 3 from sklearn.model_selection import GridSearchCV, cross_val_score, StratifiedKFold, learning_curvefrom sklearn.metrics import roc_auc_score
3.2 逻辑回归 1 from sklearn.linear_model import LogisticRegression
1 2 3
E:\Anaconda\lib\site-packages\sklearn\linear_model\_logistic.py:763: ConvergenceWarning: lbfgs failed to converge (status=1):
STOP: TOTAL NO. of ITERATIONS REACHED LIMIT.
Increase the number of iterations (max_iter) or scale the data as shown in:
https://scikit-learn.org/stable/modules/preprocessing.html
Please also refer to the documentation for alternative solver options:
https://scikit-learn.org/stable/modules/linear_model.html#logistic-regression
n_iter_i = _check_optimize_result(
LogisticRegression()
1 2 3 print ('accuracy:' ,model.score(valid_x,valid_y))print ('roc_auc:' ,roc_auc_score(valid_y,model.predict_proba(valid_x)[:,1 ]))
accuracy: 0.9392022693730474
roc_auc: 0.4928235566543885
使用默认参数训练出的模型基本等于无效,这里我们尝试借助 GridSearchCV函数调试参数。
1 2 3 4 5 6 7 8 9 "solver" :["liblinear" ,"saga" ], "C" :[0.01 ,0.1 ,1 ,10 ,100 ],"penalty" :["l1" ,"l2" ]5 ,scoring = "roc_auc" )
1 grid_search.fit(train_x,train_y)
1 2 3
1 2 3 4 5 6 7 8 9 10 11 0.1 , penalty = 'l1' ,solver='liblinear' )1 ])print ('accuracy:' ,LG.score(valid_x,valid_y))print ('roc_auc:' ,auc_lr)
accuracy: 0.9389339313437985
roc_auc: 0.6699541453628105
1 2 1 ]
3.3 随机森林 1 from sklearn.ensemble import RandomForestClassifier
1 2 3
RandomForestClassifier()
1 2 3 4 1 ])print ('accuracy:' ,model.score(valid_x,valid_y))print ('roc_auc:' ,auc_rf)
accuracy: 0.9390297663542445
roc_auc: 0.6500745133672414
1 2 3 4 5 6 7 8 9 "n_estimators" :[50 ,100 ], "max_depth" :[5 ,10 ,100 ],"min_samples_split" :[2 ,10 ,500 ],"min_samples_leaf" :[1 ,50 ,100 ]3 ,scoring = "roc_auc" )
1 grid_search.fit(train_x,train_y)
1 2 3
1 2 3 4 5 6 7 8 9 10 11 100 ,min_samples_leaf=50 ,min_samples_split=10 )1 ])print ('accuracy:' ,RF.score(valid_x,valid_y))print ('roc_auc:' ,auc_rf)
accuracy: 0.9392022693730474
roc_auc: 0.6848666816975427
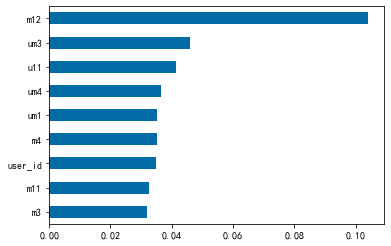
1 2 3 9 :].plot.barh()
<AxesSubplot:>
重要性排名前三的特性为:商家用户复购率,用户购买点击比和用户-商家交互过的商品数。
1 2 1 ]
3.4 LightGBM 1 from lightgbm import LGBMClassifier
1 2 3
LGBMClassifier()
1 2 3 4 1 ])print ('accuracy:' ,model.score(valid_x,valid_y))print ('roc_auc:' ,auc_lgbm)
accuracy: 0.939163935368869
roc_auc: 0.6842040668650429
1 2 3 4 5 6 7 8 9 10 11 12 "boosting_type" :["gbdt" ,"dart" ,"goss" ],"learning_rate" :[0.05 ,0.1 ],"n_estimators" :[100 ,1000 ],"num_leaves" :[30 ,100 ,500 ],"max_depth" :[10 ,50 ,100 ],"subsample" :[0.5 ],"min_split_gain" :[0.05 ]3 ,scoring = "roc_auc" )
1 grid_search.fit(train_x,train_y)
1 2 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 "dart" ,0.05 ,10 ,0.05 ,1000 ,30 ,0.5 1 ])print ('accuracy:' ,LGBM.score(valid_x,valid_y))print ('roc_auc:' ,auc_lgbm)
accuracy: 0.939163935368869
roc_auc: 0.687943355403638
1 2 3 import lightgbm10 )
<AxesSubplot:title={'center':'Feature importance'}, xlabel='Feature importance', ylabel='Features'>
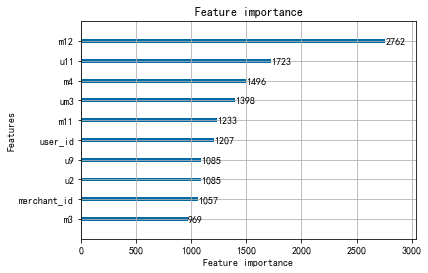
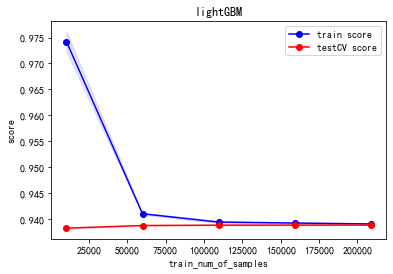
重要性排名前三的特性为:商家用户复购率,用户购买点击比和商家被交互过的品类数。
1 2 1 ]
3.5 XGBoost 1 from xgboost import XGBClassifier
1 2 3
XGBClassifier(base_score=0.5, booster='gbtree', callbacks=None,
colsample_bylevel=1, colsample_bynode=1, colsample_bytree=1,
early_stopping_rounds=None, enable_categorical=False,
eval_metric=None, gamma=0, gpu_id=-1, grow_policy='depthwise',
importance_type=None, interaction_constraints='',
learning_rate=0.300000012, max_bin=256, max_cat_to_onehot=4,
max_delta_step=0, max_depth=6, max_leaves=0, min_child_weight=1,
missing=nan, monotone_constraints='()', n_estimators=100,
n_jobs=0, num_parallel_tree=1, predictor='auto', random_state=0,
reg_alpha=0, reg_lambda=1, ...)
1 2 3 4 1 ])print ('accuracy:' ,model.score(valid_x,valid_y))print ('roc_auc:' ,auc_xgb)
accuracy: 0.9386847603166388
roc_auc: 0.6774144828554727
1 2 3 4 5 6 7 8 9 10 11 12 "eta" :[0.05 ,0.1 ],"gamma" :[5 ,50 ,200 ],"min_child_weight" :[10 ,100 ,1000 ],"max_depth" :[5 ,50 ,100 ],"subsample" :[0.5 ],"objective" :["binary:logistic" ],"eval_metric" :["auc" ]3 ,scoring = "roc_auc" )
1 grid_search.fit(train_x,train_y)
1 2 3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 0.1 ,5 ,50 ,100 ,"binary:logistic" ,"auc" ,0.5 1 ])print ('accuracy:' ,XGB.score(valid_x,valid_y))print ('roc_auc:' ,auc_xgb)
accuracy: 0.9392022693730474
roc_auc: 0.6886825861417296
1 2 3 import xgboost10 )
<AxesSubplot:title={'center':'Feature importance'}, xlabel='F score', ylabel='Features'>
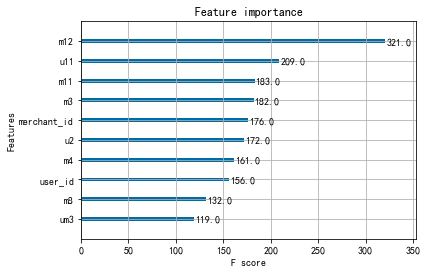
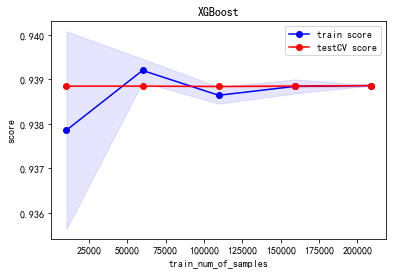
重要性排名前三的特性为:商家用户复购率,用户购买点击比和商家购买点击比。
1 2 1 ]
3.6 基模型结果分析 比较各模型结果如下:
1 2 3 4 "auc" :[auc_lr,auc_rf,auc_lgbm,auc_xgb],"model" :["LogisticRegression" ,"RandomForest" ,"LightGBM" ,"XGBoost" ]})"auc" ,ascending=False )
auc
model
3
0.688683
XGBoost
2
0.687943
LightGBM
1
0.684867
RandomForest
0
0.669954
LogisticRegression
比较各模型auc分数,LightGBM预测模型的表现最好,其auc分数为0.6885。而在针对各模型的特征重要性的排序中,用户的购买点击比、商家的用户复购率这两个特性在各模型中都排在前列,对模型的影响最大。
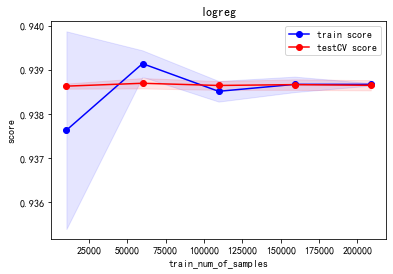
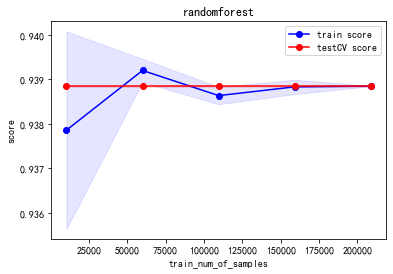
我们试着绘制训练和验证过程的学习曲线,对各个单模型是否存在过拟合或者欠拟合等情况进行探究。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 def plot_learning_curve (clf, title, X, y, ylim=None , cv=None , n_jobs=3 , train_sizes=np.linspace(.05 , 1. , 5 ):1 )1 )1 )1 )111 )if ylim is not None :u"train_num_of_samples" )u"score" )0.1 , color="b" )0.1 , color="r" )'o-' , color="b" , label=u"train score" )'o-' , color="r" , label=u"testCV score" )"best" )1 ] + train_scores_std[-1 ]) + (test_scores_mean[-1 ] - test_scores_std[-1 ])) / 2 1 ] + train_scores_std[-1 ]) - (test_scores_mean[-1 ] - test_scores_std[-1 ])return midpoint, diff'logreg' , 'randomforest' , 'lightGBM' , 'XGBoost' ]0 ], alg_list[0 ], X, Y)1 ], alg_list[1 ], X, Y)2 ], alg_list[2 ], X, Y)3 ], alg_list[3 ], X, Y)
(0.9388542876912196, 2.403725037580795e-05)
K-折交叉验证(Accuracy) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 10 for classifier in clfs :"accuracy" , cv = kfold, n_jobs=4 ))for cv_result in cv_results:'logreg' , 'randomforest' , 'lightGBM' , 'XGBoost' ]"CrossValMeans" :cv_means,"CrossValerrors" : cv_std,"Algorithm" :ag})"CrossValMeans" ,"Algorithm" ,data = cv_res, palette="Blues" )"CrossValMeans" ,fontsize=10 )'' )30 )"10-fold Cross validation scores" ,fontsize=12 )
E:\Anaconda\lib\site-packages\seaborn\_decorators.py:36: FutureWarning: Pass the following variables as keyword args: x, y. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
1 2 3 for i in range (4 ):print ("{} : {}" .format (ag[i],cv_means[i]))
logreg : 0.9386500242771005
randomforest : 0.9388493622744981
lightGBM : 0.9388455288006042
XGBoost : 0.9388608622553315
4. Bagging 比较各模型auc分数,XGBoost和LightGBM预测模型的表现已经很不错。在许多分类问题上集成学习可以带来一下几种可能的好处:
提高模型整体的泛化能力
降低陷入局部极小的风险
提升模型预测的稳定性
因此,我们将四种基模型进行Bagging集成,并测试其性能表现
4.1 集成模型的建立 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class Bagging (object def __init__ (self,estimators ):for i in estimators:0 ])1 ])def fit (self, train_x, train_y ):for i in self.estimators:for i in self.estimators]).Tdef predict_proba (self,x ):1 ] for i in self.estimators]).Treturn self.clf.predict_proba(x)[:,1 ]def score (self,x,y ):return s_auc
选择模型进行 Bagging
1 bag = Bagging([('logreg' ,LG),('RandomForests' ,RF),('LightGBM' ,LGBM),('XGBoost' ,XGB)])
4.2 测试模型表现 同样基于roc_auc_score,这里我们进行10轮,最终取平均成绩
1 2 3 4 5 6 7 8 9 10 11 score = 0 for i in range (0 ,10 ):0.20 10
0.6899103572351627
与单个学习器中表现最好的XGBoost模型相比(roc_auc_score=0.688683),Bagging模型的表现还是有明显的提升。
4.3 进行预测 为使模型更充分地学习已有训练数据,接下来使用全部的已知标签数据训练模型,然后使用该集成模型对未知数据进行预测
1 2 3 4 5 6 7 8 9 'user_id' ,'merchant_id' ]] = test[['user_id' ,'merchant_id' ]]'prob' ] = prob_bagging'./data/submission.csv' ,index=False )
参考声明 本报告的实现参考了以下内容: